点击左侧的归档可以看到我的博客的目录!
Click 归档 to see the table of content of my blogs!
遗憾的是,我目前嵌入的评论区并不能正常工作,等我有时间再搞一下......
断断续续一周时间搓出来的地球流体的数值模拟与AI预测课程大作业,先放一个文件链接在这里以便下载查看,考完期末再来补充项目的具体实现过程。
这是“地球流体的数值模拟与AI预测”课程的大作业,这门课程由杨邱老师和闻新宇老师讲授。这门课在开学后不久就开始征集大家的大作业选题,我对机器学习比较感兴趣,同时之前也没有独立做过什么像样的机器学习相关的项目,所以在选题的时候希望选一个机器学习在大气科学中的应用。在经过一些文献调研和让GPT给我提供idea之后,我敲定了行星大气光谱反演这个主题,杨邱老师也认为这是一个不错的选题,并且建议我可以去找一些做观测的老师们聊聊,用观测数据进行训练和比对会让结果更具有说服力。杨老师的建议很好,但是人都是有惰性的,从确定完选题之后我就基本上没有再投入过任何行动,直到距离最后的presentation还有一周多的时候,我才意识到ddl的紧迫性,开始认真着手这个项目。
首先我需要确定我需要做的东西是什么,我最初的想法是从行星大气光谱中反演出大气的成分和温度廓线。但是仔细一想就有很多问题:这个成分
MITgcm是一个用于研究大气、海洋与气候的数值模式,它是一个基于有限体积法的非静力平衡模式。MITgcm巧妙地通过流体动力学方程的同构,使得其动力内核既可以进行大气运动的模拟,也可以进行海洋流动的模拟。
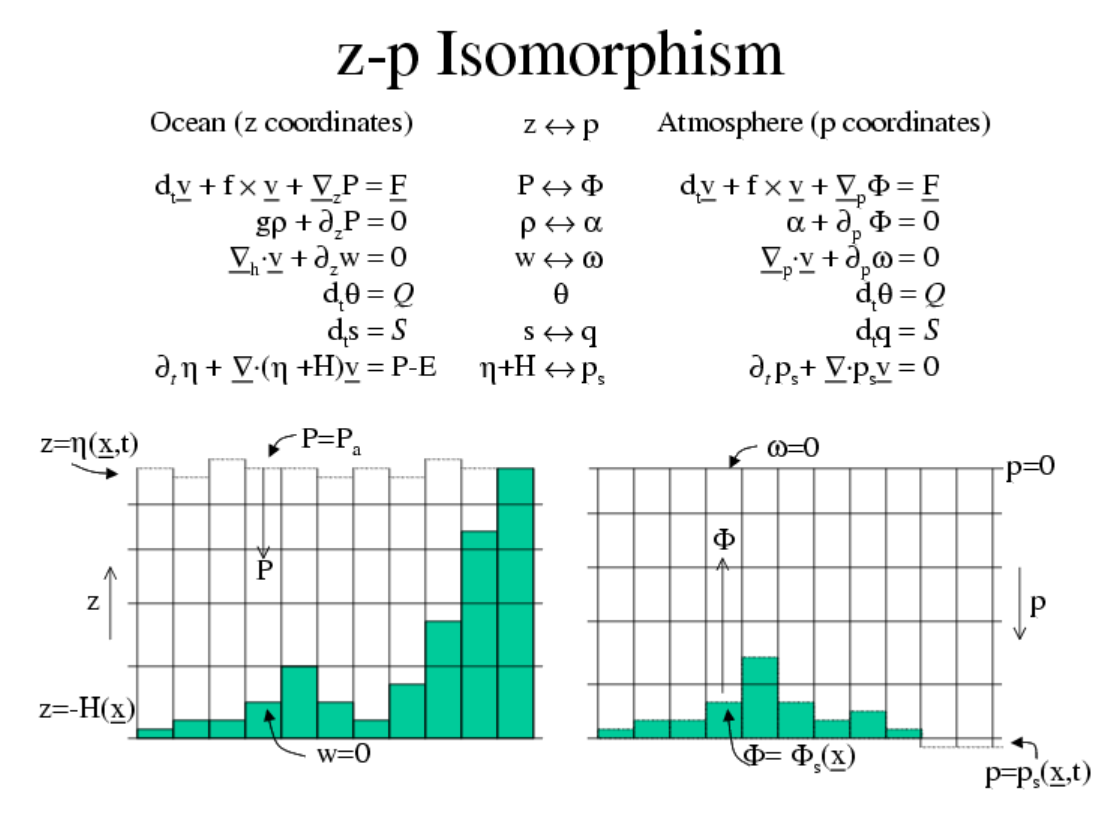
如果对MITgcm模式的方程和数值算法感兴趣,可以参考MITgcm的官方文档,里面对于模式的kernel、参数化方案等有较为详细的介绍。
首先我们需要获取MITgcm的代码,可以通过git进行:
1 | git clone https://github.com/MITgcm/MITgcm.git |
如果git不可用,也可以直接访问MITgcm的github页面手动下载解压。
下载之后,cd进入MITgcm的根目录,应该包含以下内容:
1 | model #包含主程序源码 |
接下来我们需要选定一个想要进行的实验,编译将在此基础上进行。所有的样例实验都存放在verification目录下,本文将以tutorial_baroclinic_gyre为例进行演示,进行其他实验的步骤类似。我们首先进入目标实验的编译目录:
1 | cd verification/tutorial_baroclinic_gyre/build |
接着,需要生成Makefile:
1 | ../../../tools/genmake2 -mods ../code -optfile ../../../tools/build_options/linux_amd64_gfortran |
其中-mods命令告诉genmake使用../code中的内容覆盖模型默认的源码,包括SIZE.h(配置模式的区域大小,后面介绍);-optfile命令告诉genmake在执行期间运行指定的optfile,这是一个bash脚本,包含环境变量、路径、编译器选项等,MITgcm提供了非常多预置的optfile,位于tools/build_options目录下,可以根据自己的机器进行选择。
生成Makefile之后,我们通过以下命令创建依赖关系:
1 | make depend |
最后,可以使用以下命令编译代码:
1 | make |
如果成功编译,会生成一个名为mitgcmuv的可执行文件,因为编译后build目录内文件较多,可以使用stat mitgcmuv来方便地检查编译是否成功进行。
tutorial_baroclinic_gyre为例我们从MITgcm的根目录进入运行目录:
1 | cd run |
目前这是一个空目录,我们需要将可执行文件和输入文件放置进来:
1 | cp ../build/mitgcmuv . |
这样,我们就做好了运行前的全部准备,可以直接运行
1 | ./mitgcmuv |
样例实验通常默认了非常少的时间步数,运行后立刻可以得到结果,可以将输出与../results/output.txt进行对比,如果结果相同,则说明程序执行正常,我们接着可以开始对实验参数进行更具体的配置。
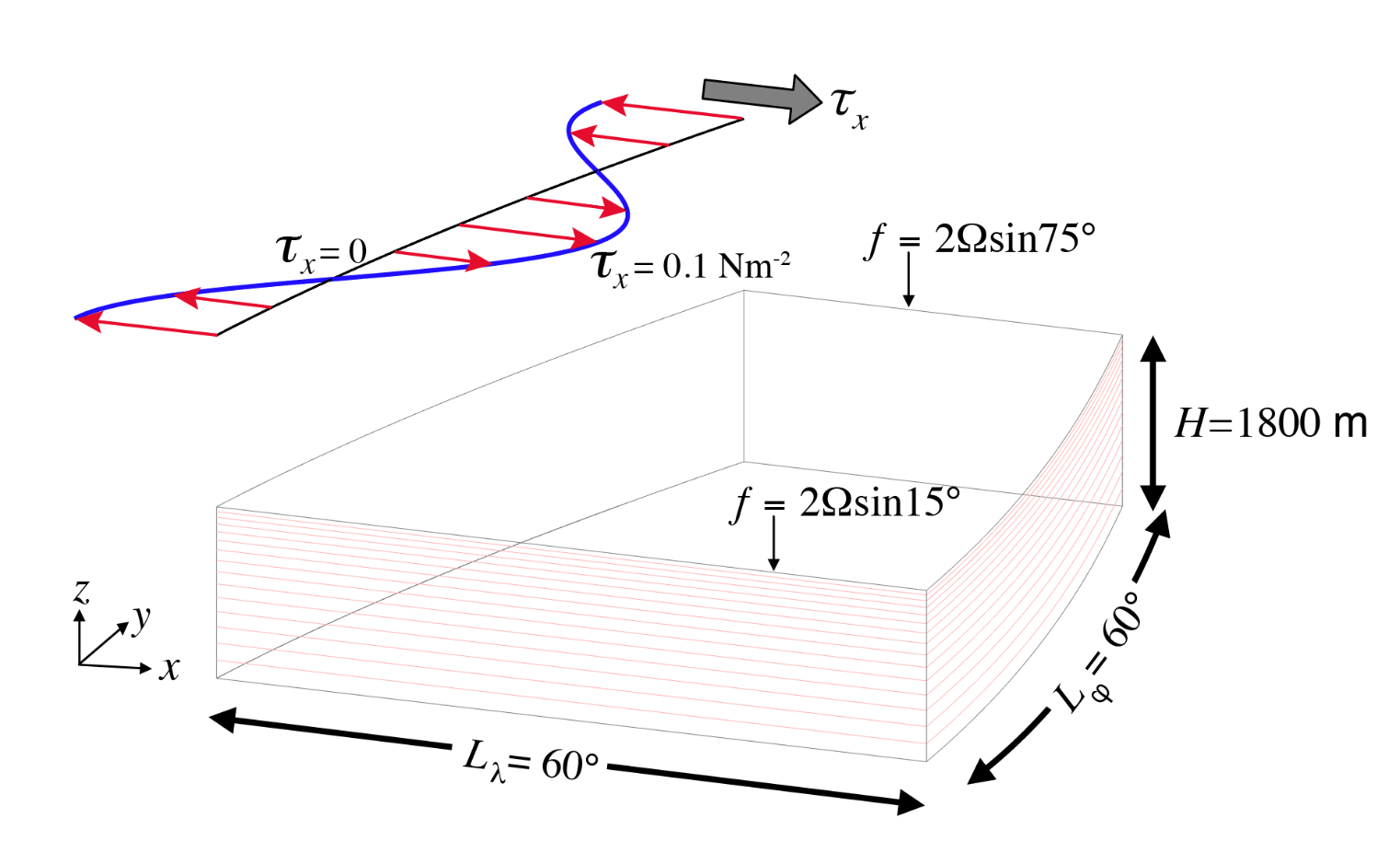
本文运行的实验是Baroclinic Ocean Gyre,模拟风和浮力强迫下的斜压双涡漩海洋环流,位于verification/tutorial_baroclinic_gyre目录下。本实验使用球坐标网格并设有15个垂直层,横跨热带到中纬度,并受到恒定的东西风应力强迫,并且风应力的强度在南北方向上成正弦变化。
接下来我们对实验中的参数进行配置,配置分为两部分:编译配置和运行配置,编译配置需要在编译前进行,每次修改之后都需要重新编译,而运行配置则不需要。
code/packages.conf1 | packages.conf文件应该包含以下内容: |
在这个文件中我们指定了我们希望包含的库。gfd是一个预定义的库组,包含了大多数设置所需要的标准库。mnc库用于将输出以netCDF格式存储;diagnostics库允许用户从用于模型诊断的众多变量中选择输出,并指定输出频率,提供多种时间平均和快照选项,如果没有启用这个库,输出将局限于少量的快照。
code/SIZE.h这个文件指定了模型的几何。以下代码计算了整个模型域的水平大小:
1 | & Nx = sNx*nSx*nPx, |
整个模型域的大小是$62\times 62$,我们在这里将模型在水平方向上划分成四个区块,每个区块的大小为$31\times 31$,也就是
1 | & sNx = 31, |
为了正确地处理边界条件,模型的区块需要具有一定的重叠区域(overlap),MITgcm许可的最小的overlap是2,对于更加复杂的对流方案或参数化方案可能需要更大的overlap,我们在这里保持2即可:
1 | & OLx = 2, |
以下代码设置了nPx和nPy,分别表示在$x$和$y$方向上使用的进程数量,我们暂时使用单进程,因此这两个参数设置为1:
1 | & nPx = 1, |
最后,我们指定模型具有15个垂直层:
1 | & Nr = 15) |
修改完上述参数后,别忘记重新编译。
input/data文件里包含了模型的大部分参数,可以根据自己的需要进行修改。
第一部分主要是物理参数设置:
1 | Model parameters |
另一部分比较重要的是对时间参数的设置:
1 | startTime=0., #开始时间 |
input/bathy.bin和input/windx_cosy.bin文件称分别指定了海底的地形以及风应力,这两个文件可以通过input/gendata.m或input/gendata.py生成。
完成对所有参数的的修改之后,就可以正式进行模式的运行了,可以将程序提交后台,并将日志输出到文件中:
1 | ./mitgcmuv > output.log & |
程序运行结束之后,可以查看日志文件的末尾,如果显示
1 | PROGRAM MAIN: Execution ended Normally |
则说明程序顺利完成。此时run目录下会有很多pickup.*文件,这些文件可以用来restart,也就是从某个时间点开始运行,这样即使我们的程序中途退出了,我们也不需要再次从$t=0$开始运行。
由于我们开启了mnc功能,我们可以获得netCDF格式的输出文件,这些文件被存放在run/mnc_test_[iter]子目录下,iter从0001开始,每次重新运行程序都会递增1。
由于我们在运行的时候将模型分为了4个区块,因此数据也是分4个区块存储的,MITgcm提供了便捷的工具将结果合并为完整的netCDF文件,我们可以在运行目录run下执行:
1 | ln -s ../../../utils/python/MITgcmutils/scripts/gluemncbig . |
主要的netCDF输出文件包括:
grid.nc:包含模型网格变量state.nc:包含状态变量($U, V, W, Temp, S, Eta$)的快照surfDig.nc:包含data.diagnostics的列表1指定的二维诊断量(ETAN, TRELAX, MXDEPTH等)dynDiag.c:包含列表2指定的三维诊断量(THETA, PHIHYD, UVEL, VVEL, WVEL等)dynStDiag.nc:包含统计-动力学诊断量phiHyd.nc, phiHydLow.nc:分别为静水压势异常的三维快照场和底部静水压势异常的二维快照场我们将模型运行100年,查看系统达到稳态之后的状态。由于系统运行所需的时间较长,且占用存储空间较大,我们在本文中就不改变参数进行实验了,我们将对单次运行之后得到的结果进行分析。
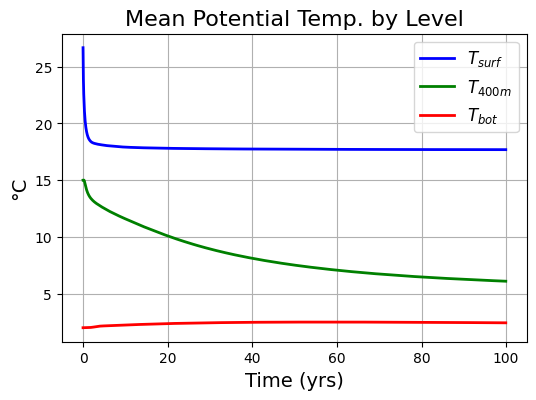
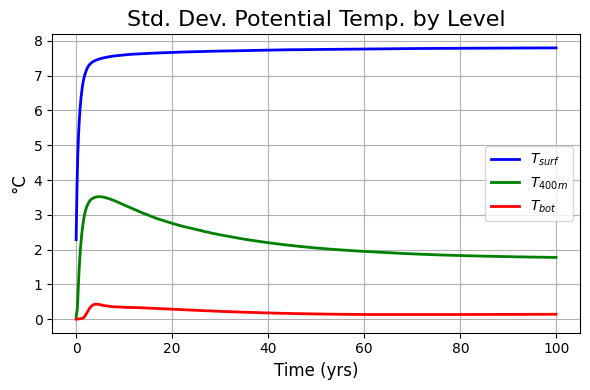
模型表层的温度最开始为$30^\circ C$,在外界的forcing下表层温度迅速降低,从图3中可以看到在最开始的5年内,表层温度差不多就达到了平衡,而深度的海水温度变化比较缓慢。从图4中可以看到,表层海水的梯度较大,水平方向上分布不均匀,而深层海水的水平方向比较均匀。
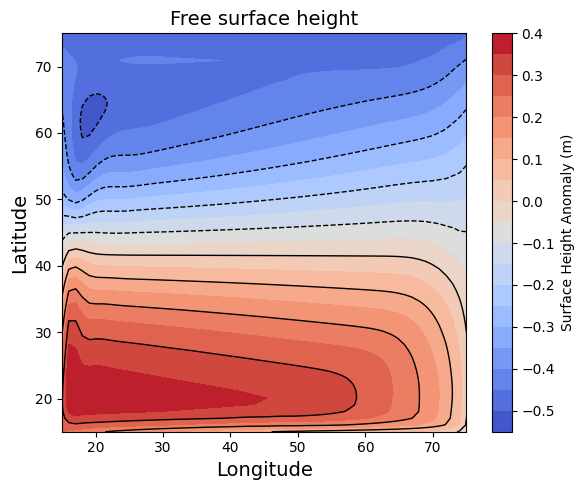
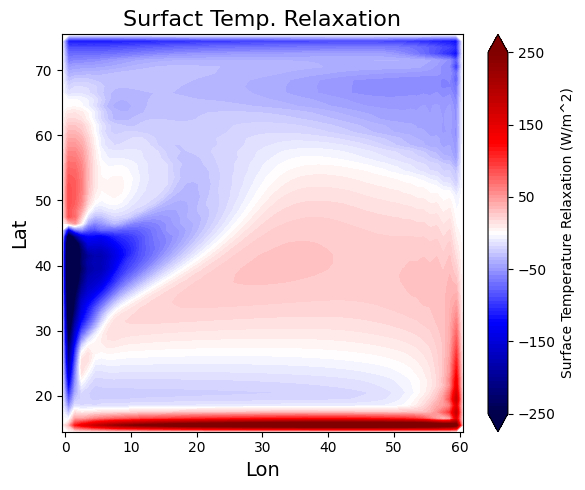
模型在运行到100年的时候已经很接近稳态了,我们取这一年的年平均数据进行分析。图5显示了海平面的高度,可以看到在风应力和科里奥利力的作用下,海平面的高度呈现南高北低。图6显示了温度弛豫的分布,我们可以看到海水与外界的热量交换在水平方向上是怎么分布的,表层海水在内部输送和表面交换的作用下达到热量平衡。
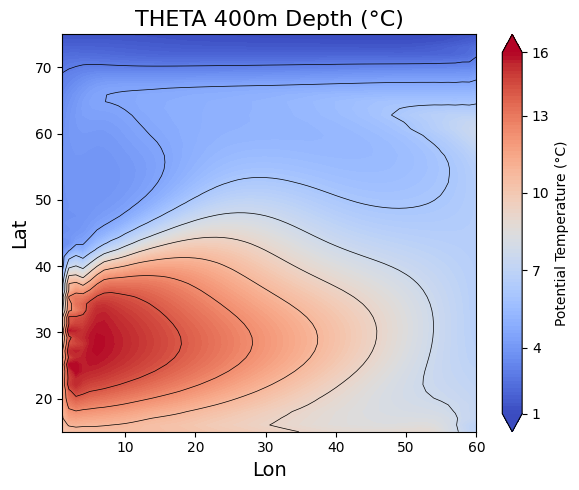
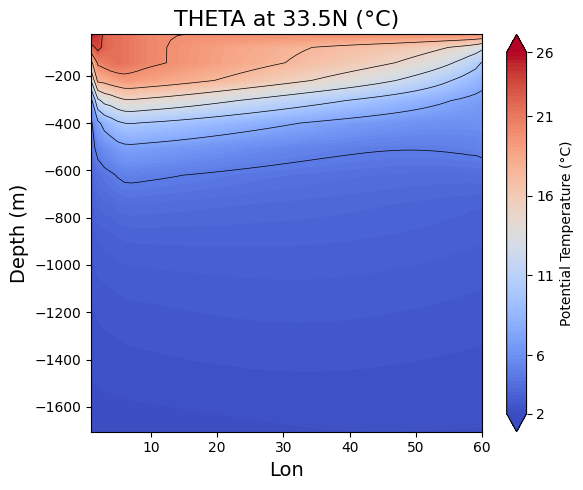
我们还可以观察海水内部的温度是如何分布的,图7和图8分别显示了在400m深度和北纬$33.5^\circ$处的温度分布。
本文介绍了MITgcm模式的安装、编译与运行过程。MITgcm功能强大、使用方便,如果想要更深入地学习,可以访问官方文档,里面不仅包含对本文所有内容的介绍,还有对所有tutorial实验的讲解,以及更加灵活的物理过程和参数化方案的配置。
WRF (Weather Research and Forecasting) 模式是一个开源、灵活、模块化的数值天气预报和大气模拟工具。
WRF模式的结构如图所示,其最为核心的部分是可执行程序wrf.exe(后缀仅仅是出于习惯,因为Linux并不以后缀标识文件类别)。
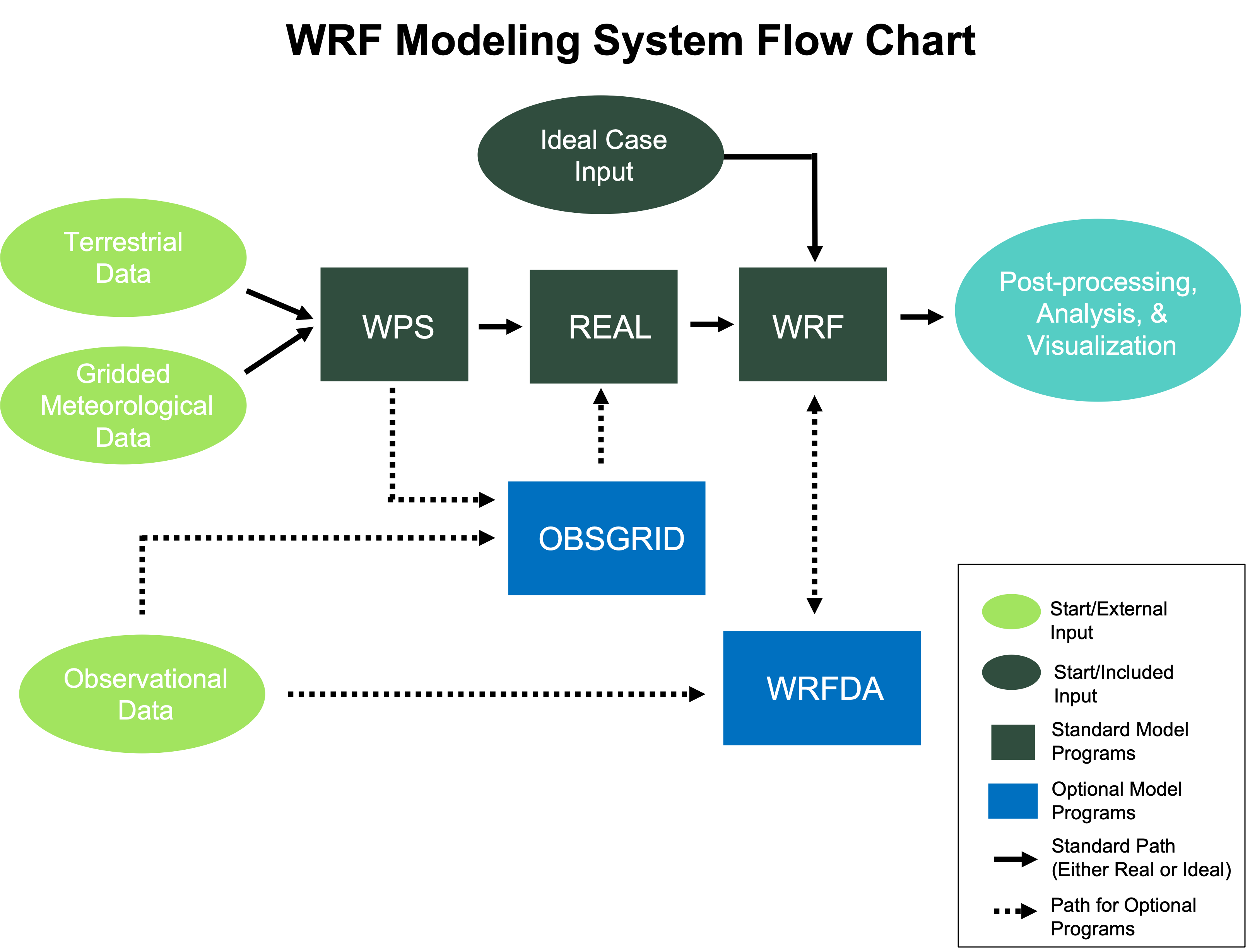
WRF模型可以运行两种不同的模拟:ideal和real。理想实验通常利用已有的sounding数据为WRF模型生成初始条件,而真实模拟则要求利用WPS(WRF Preprocessing System)进行前处理,将真实的测量数据转化为WRF模型的初始条件。WRF模型的可执行文件(wrf.exe)本身并不随着实验类型的不同而改变,但是这两种不同的实验对应两种不同的前处理程序,分别是ideal.exe和real.exe,它们都需要在WRF模式运行之前执行。
WRF的运行通常分为以下几个阶段:
本文的后几个部分会分别介绍第1,3,4个步骤。步骤2是专为真实模拟而进行的预处理,感兴趣的读者可以自行查阅WRF官方文档。
对于如何准备系统环境和编译WRF,官方有一个详细的指南:How to Compile WRF: The Complete Process,这里仅做一个简单的介绍。
WRF模式运行所必不可少的库有且仅有NetCDF,同时如果想要进行并行运算,还需要安装OpenMPI。安装之后可以通过ncdump --version和mpirun --version来检查自己是否安装成功,以及查看软件的版本。
可以直接git clone:
1 | git clone https://github.com/wrf-model/WRF |
如果遇到网络问题,也可以到github上手动下载。
下载解压之后,WRF的目录中应该有如下内容:

首先运行
1 | ./configure |
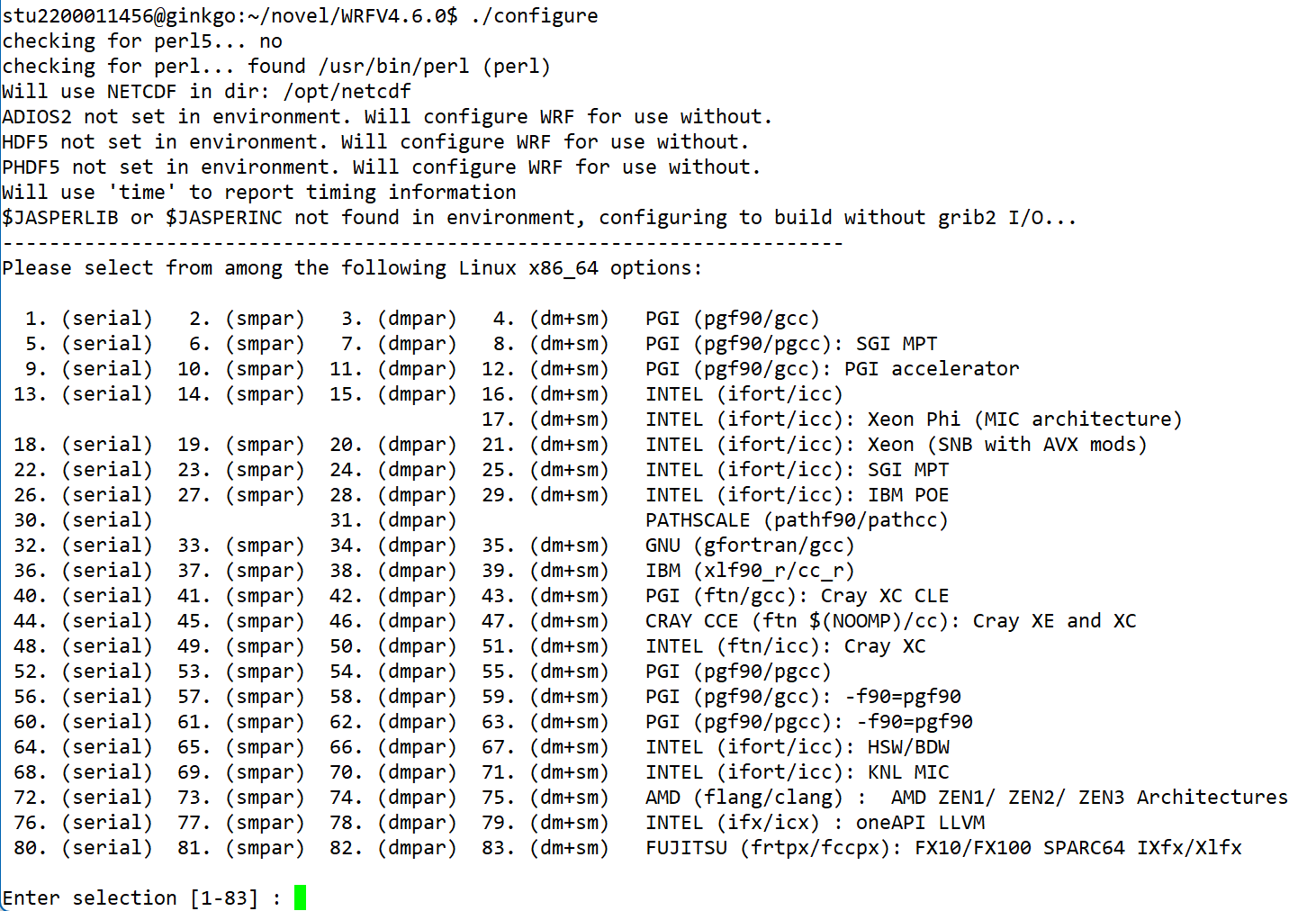
在出现的列表中根据系统和编译器选择合适的选项,并根据需要选择串行或并行(并行需要有OpenMPI库的支持)。选择之后还需要对嵌套网络进行选择,对于简单情况直接保持默认即可。
配置之后,在目录中应该会出现一个名为configure.wrf的文件。此时对于4.5.x/4.6.x的版本,还需要进行一步额外的操作才能成功编译,需要在configure.wrf文件的LIB_EXTERNAL的最后添加-lnetcdf,而对于更老的版本4.2.x/4.3.x/4.4.x,则不需要进行这步操作。
之后就可以直接进行编译了。首先我们可以打开 test 目录查看可用的理想实验,包括


确定自己要运行的理想实验之后,回到 WRF 目录,输入
1 | ./compile -j 4 em_grav2d_x |
其中,-j 4代表使用4个线程进行并行编译,这个选项不是必须的,可以根据需要删去或更改;em_grav2d_x是本文中理想实验的名称,可以替换成test目录中的其他理想实验。
如果编译没有问题,应该会显示”Executables successfully built”,这是我们进入理想实验的目录test/em_grav2d_x,可以看到出现了可执行程序ideal.exe和wrf.exe。
em_grav2d_x为例本文采用的理想实验是em_grav2d_x,用于模拟二维重力流。该实验基于Straka等人1993年发表的文章[1],在X-Z平面进行,水平方向满足周期性边界条件。
在运行程序之前,首先需要配置实验参数,这些参数在namelist.input文件中定义,其具体含义可以参见README.namelist,与本实验有关的参数及其含义如下:
1 | run_minutes = 15, ! 模拟时长:15 分钟(控制模拟的时间范围) |
接着可以通过input_sounding文件设置初始大气的垂直廓线,文件夹中给出了静止大气的廓线和'input_sounding.um=20',也就是有20m/s的水平风速的廓线,当然也可以根据需要自己定义大气的初始廓线。
完成参数和初始廓线的配置之后,就可以运行初始化程序./ideal.exe,注意,每次修改完namelist.input及input_sounding文件之后,都需要重新运行ideal,否则修改将不会生效。
之后我们就可以运行主程序了
1 | ./wrf.exe & |
命令最后的&表示将程序提交到后台运行,这样即使前台的进程退出,程序依然可以正常工作。
如果想要中止之前的任务,可以先利用top命令查看自己作业的进程ID(PID),之后在命令行输入kill <PID>就可以结束掉该进程。
程序运行的结果将会保存在wrfout_d01_0001-01-01_00_00_00中,可以利用NCL等工具进行分析和后处理。
WRF模式支持多种分析结果的方式,包括NCL, RIP, ARWpost, UPP和VAPOR。程序默认输出的文件是netCDF格式的,可以利用NCL方便地进行处理。
作为简易快捷的查看方式,ncview可以让我们立刻观察到结果。但是为了更清晰地分析结果,可以使用NCL语言或者python的netCDF4库。
对于默认的初始参数,程序运行的结果如下:
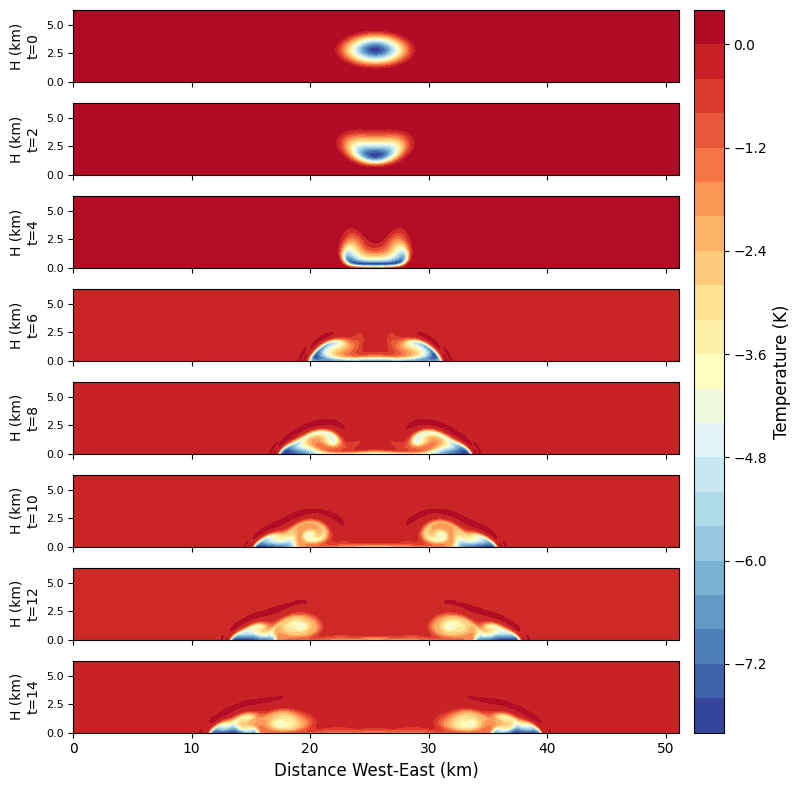
可以看到,这团冷空气下落到地面的过程中就在水平方向上不断延展,之后会断裂成左右对称的两部分,并继续沿着地面移动。
我们可以改变实验中的参数,观察对于结果有什么影响。
input_sounding文件中的水平风速场,将水平风速分别设置为0,20,40,得到的结果如下(从上到下风速依次为0,20,40):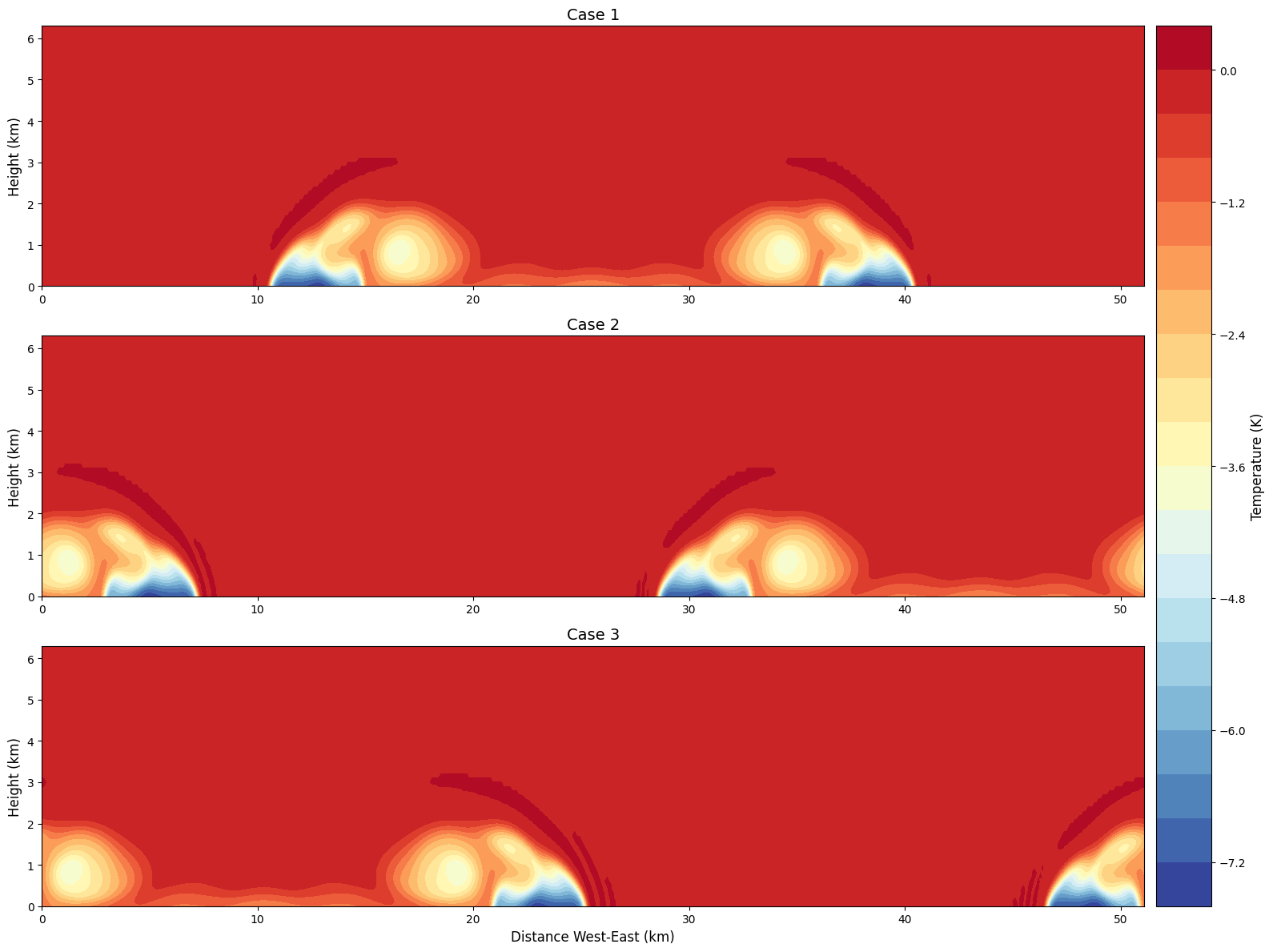
可以看到,水平的风速对于系统仅有一个水平方向随时间平移的作用,对于气团的结构则几乎没有影响。
namelist.input.dx=200和namelist.input.dx=400文件,得到的结果如下(从上到下分辨率依次为100,200,400):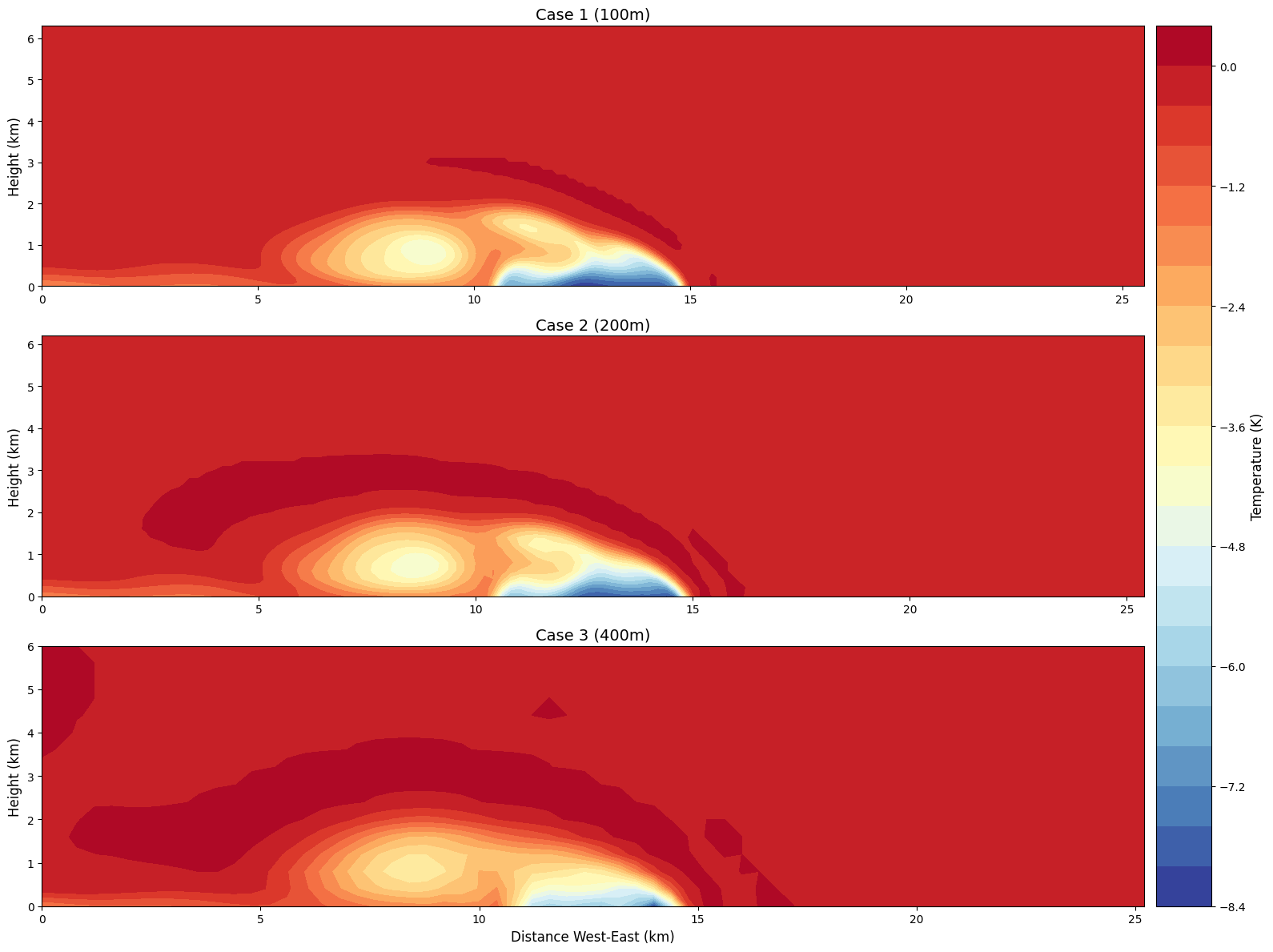
分辨率降低的时候,程序运算的时间显著减少,但是代价是失去了气团的精细结构。
namelist.input中的khdif和kvdif,得到的结果如下(从上到下扩散系数分别为50,75,100,其中75是默认值):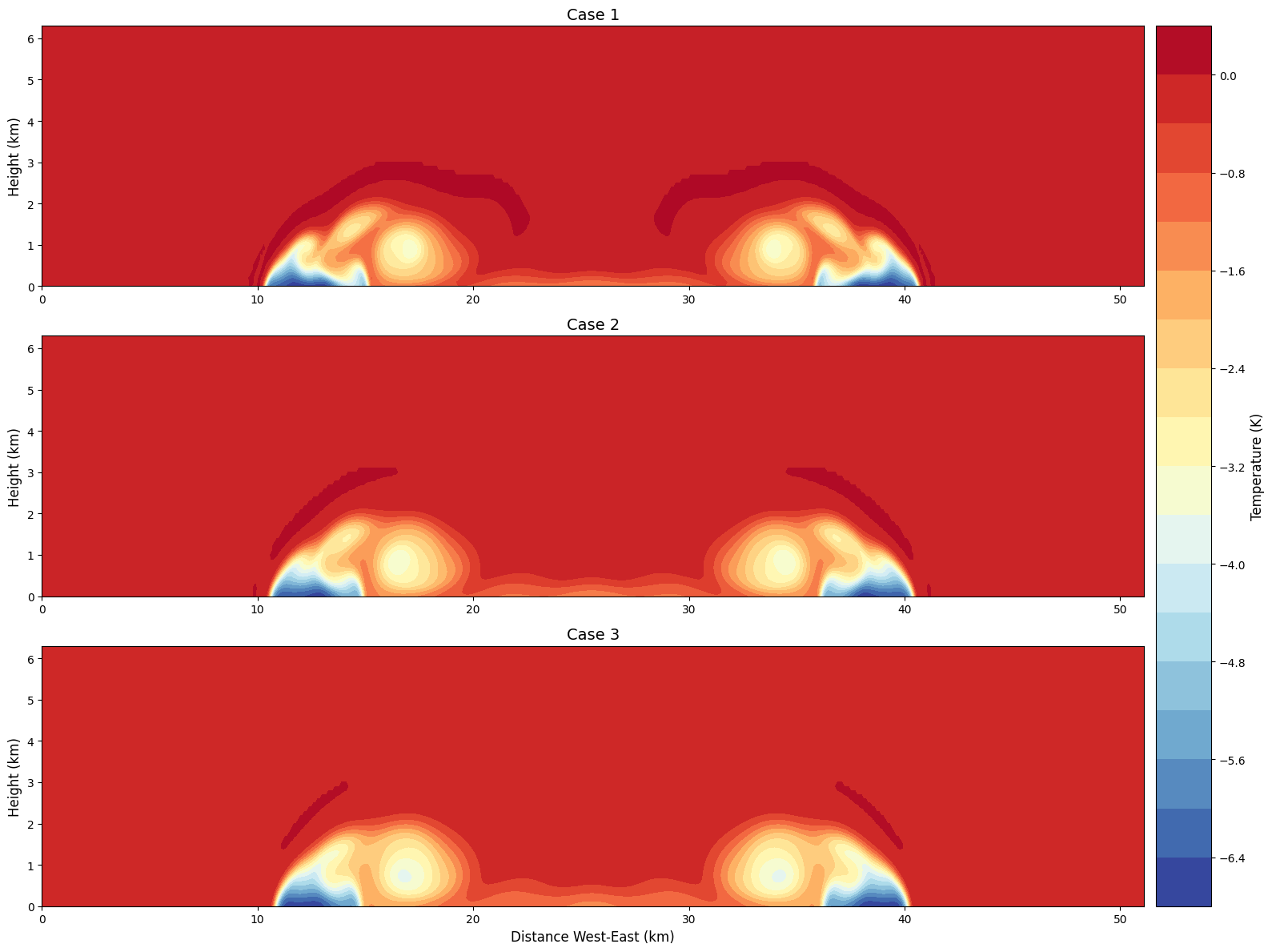
综上,我们成功地编译并运行了WRF模式,并对em_grav2d_x这个简单的二位重力流问题进行了理想实验。
这是我的批判性思维与学术写作课程的课程论文,这门课和我最初想象中的学术写作有一定的距离,这门课更加面向人文社科类的学术写作,而不是我更加希望的科学写作。这门课上的时候给我带来了不少的痛苦,但是整个课程上下来也就与之和解了,平心而论还是有一些收获的。
我的论文的pdf版可以在这里看到,下面是原文:
In previous studies, the challenges of this new technology have been examined, indicating the huge impact BCIs might exert on human society (Maiseli et al., 2023). This article first presents a brief review of the development and applications of BCIs, followed by a detailed discussion on potential ethical and legal issues which might arise along with the BCI technology. To address these challenges, the article proposes a range of solutions.
Brain-computer interfaces, as the name suggests, are the technology that facilitate the interaction between human brain and the machines. Early attempts to collect and analyze human brain signals began in the last quarter of the 19th century (Stone & Hughes, 2013), but it is only in the past decade that the field has been flooded with breakthroughs. Moreover, combined with deep brain stimulation (DBS) technology, BCIs are not limited to merely analyzing brain signals; they can also influence and directly stimulate them. Complex brain activities concerning emotions and cognitive process are essential aspects of human existence (UNESCO, 2023). Being able to capture and manipulate the human brain, BCIs are capable of achieving what beyond our imagination. The medical function is undoubtedly a priority in the application of the BCIs. BCIs can enable individuals with disabilities to control artificial limbs or to communicate through thought. In the world of entertainment, BCIs hold great promises to provide each consumer with unique experiences based on their neural signals (Steffen & Orsolya, 2020). With sufficient funding and high research enthusiasm, BCIs are expected to reach commercialization in the near future, extending their application across various domains.
All technologies have their pros and cons, and BCIs are no exception. With the rapidly advancing development of this technology, which is intimately connected to the human mind, we are obliged to fully investigate the implications of this brand-new technology on human society. Similar to other bio-technologies, BCIs are having a profound impact on what it means to be a human, thereby challenging the moral and ethical compass of human society, as well as the legal frame which can only set restraints on existing technologies.
When it comes to monitoring our neural activity, the privacy problem stands a prior concern. Imagine how it feels to have your diary read by someone else, being monitored by a BCI is thousands of times worse. BCIs may potentially deprive us of our mental privacy, collect our neural data without our permission. Neural data, or personal brain data, are data containing information about the brain structure and working pattern. According to UNESCO (2021), a great amount of neural data are generated by our brain unconsciously, which can be collected by BCI devices without our knowledge, implying the fact that we are losing our mental privacy without even realizing it. This leakage of neural information may cause discriminatory practices. Like hepatitis B patients, people who are subconsciously depressed or violent can also be discriminated against in the workplace, making it harder for them to find work. The current legal system is inadequate in preventing large companies from infringing on citizens’ privacy (Sampson, 2021). The inexplicable nature of the human mind makes it even harder to clarify and therefore regulate the practice of intruding individual’s mental privacy.
The acquisition of detailed information about one’s thoughts also means a more profound understanding of behavior patterns and deep desires. Take a comparison between the recommendations on your social media with those of your friends, you will be amazed at the power of big data. Yet the current recommendations are merely based on your past behaviors. Presume that your brain activities, including subconscious feelings, are at full exposure to the BCIs, and these data are transmitted to third-party companies, then you will be trapped in the information cocoon woven by big companies for good. Under such circumstances, no decision can be free from influence of BCIs, which significantly undermines human autonomy, which refers to the ability to perform self-directed action without suffering from exterior interference (Beauchamp & Childress, 2001, p. 101). Another term closely related to autonomy is informed consent. The article 6 of the Universal Declaration on Bioethics and Human Rights by UNESCO (2006) states that “Any preventive, diagnostic and therapeutic medical intervention is only to be carried out with the prior, free and informed consent of the person concerned, based on adequate information.” Due to the entangled nature between human mind and BCIs, there are challenges applying the principle of informed consent to the BCI technology as the risks and benefits of this newborn technology are still in assessment.
Equity and justice are the eternal pursuit of human society (Li, 2011). The disparity in wealth leads to differences in BCI accessibility, thus posing additional challenges to social justice (UNESCO, 2021, p. 61). This issue grows even more serious if the original medical-oriented BCIs are used for cognitive enhancement. For example, transcranial direct-current stimulation (tDCS) is a technology used to restore cognitive function in people with Alzheimer’s disease and depression (Majdi et al., 2022). Combined with tDCS, BCIs are potentially capable of reinforcing the cognitive function of healthy people. As Mirza and colleagues (2019) pointed out, the rich will undoubtedly have the advantage in obtaining such service, while the poor hardly have chance to do so. This may result in differences in academic and career success and exacerbate the situation of class solidification. Therefore, ensuring equitable access to BCIs is crucial to prevent the exacerbation of social inequalities.
New technologies give rise to new modes of production and generally lead to the development of productivity forces. We should always embrace new technologies which can bring progress to humankind. However, before we release new technology from the laboratory, we must fully assess its possible impact on the society and adequately respond to it. Consequently, measures must be taken in the application of new technologies to promote social equity and justice, so as to maximize the overall well-being of human race. In response to the problems mentioned above, we propose some feasible solutions here. Currently the development of BCIs is still in the early stage and no unified standard for the industry is established. Therefore, the first task is to set up special regulatory agencies in order to implement effective supervision and unified management. Secondly, a core element to ensure the healthy development of BCI technology is transparency (UNESCO, 2021, p.74). These data are deeply related to the mental privacy and thus should in no circumstance be transmitted to a third-party corporation or organization without the fully awareness and consent of the user. Another important measure to take is to confine the function of BCIs. While BCIs possess the capacity to influence an individual’s neural activity, it is imperative to prohibit their application in this manner due to the inadequately researched nature of the potential consequences. The use of BCIs should be restricted exclusively to therapeutic applications, analogous to the regulatory approach adopted for gene-editing technologies, thereby prohibiting their utilization for enhancement purposes. By imposing such functional limitations, the issue of unequal accessibility to BCIs would be mitigated, as cognitive enhancement would not be permitted.
In the previous discussion, we have explored the rapid development and broad applications of the BCI technology. The ethical and legal issues related to BCIs are carefully examined, including invasion of mental privacy, violation of autonomy and informed consent, as well as the equitable accessibility. In order to respond to these concerns, we proposed several solutions. By establishing special regulation agencies, ensuring transparency in BCI operation and limiting the enhancement function of the BCI devices, we can minimize the potential problems that might result from the BCI technology and promote social equity and justice. The development of BCI technology marks great progress in human’s knowledge of our neural system. It is foreseeable that this technology will profoundly change our way to engage with the real and digital world. It is our common hope that such new technology can bring benefits to humanity. In this entanglement between human mind and the machine, we must preserve our mental integrity and independence. Let’s embrace this future, steering technology towards progress of human society.
References
An interface connects. (2023). Nature Electronics, 6(2), 89–89. doi:10.1038/s41928-023-00938-8
Beauchamp, T. L., & Childress, J. F. (2013). Principles of biomedical ethics (7th ed.). Oxford University Press.
Li, Q. (2011). On equity, justice and the construction of a harmonious society. In Hu, Q. (Eds.), Proceedings of 2011 International Conference on Education Science and Management Engineering (ESME 2011) ( VOLS 1-5, pp. 147–149*)*. Beijing.
Maiseli, B., Abdalla, A. T., Massawe, L. V., Mbise, M., Mkocha, K., Nassor, N. A., Ismail, M., Michael, J., & Kimambo, S. (2023). Brain–computer interface: Trend, challenges, and threats. Brain Informatics, 10(1), 20. https://doi.org/10.1186/s40708-023-00199-3
Majdi, A., van Boekholdt, L., Sadigh-Eteghad, S. & Mc Laughlin, M. (2022). A systematic review and meta-analysis of transcranial direct-current stimulation effects on cognitive function in patients with Alzheimer’s disease. Mol Psychiatry 27, 2000–2009. https://doi.org/10.1038/s41380-022-01444-7
Mirza, M. U., Richter, A., Van Nes, E. H., & Scheffer, M. (2019). Technology driven inequality leads to poverty and resource depletion. Ecological Economics, 160, 215–226. https://doi.org/10.1016/j.ecolecon.2019.02.015
Sampson, F. (2021). Data privacy and security: Some legal and ethical challenges. In: Jahankhani, H., Kendzierskyj, S., & Akhgar, B. (Eds.) Information security technologies for controlling pandemics (pp. 109-134). A. Springer, Cham. https://doi.org/10.1007/978-3-030-72120-6_4
Steinert, S. & Friedrich, O. (2020). Wired emotions: Ethical issues of affective Brain–Computer Interfaces. Science and Engineering Ethics, 26(1), 351–367. https://doi.org/10.1007/s11948-019-00087-2
Stone, J. L., & Hughes, J. R. (2013). Early history of electroencephalography and establishment of the American clinical neurophysiology society. Journal of Clinical Neurophysiology, 30(1), 28–44. https://doi.org/10.1097/WNP.0b013e31827edb2d
United Nations Educational, Scientific and Cultural Organization (UNESCO). (2006). Universal Declaration on Bioethics and Human Rights. Jahrbuch für Wissenschaft und Ethik, 11(1), 377-385. https://doi.org/10.1515/9783110186406.377
United Nations Educational, Scientific and Cultural Organization (UNESCO). (2021). Ethical issues of neurotechnology. IBC Report series. UNESCO. https://doi.org/10.54678/QNKB6229
United Nations Educational, Scientific and Cultural Organization (UNESCO). (2023). Unveiling the neurotechnology landscape. Scientific advancements innovations and major trends. UNESCO. https://doi.org/10.54678/OCBM4164
2023.9.19更新:学完统计回头来看,这只不过是一点非常fundamental的技术,似乎不值得专门挂一篇blog,但毕竟这小东西还挺别致,当时也让我着迷了一晚上,所以这篇就保留着吧。
今天看了《Statistical Data Analysis》一书中关于Monte Carlo方法的介绍,觉得非常有趣,遂动手用C将其实现,源代码在本篇blog的结尾处。
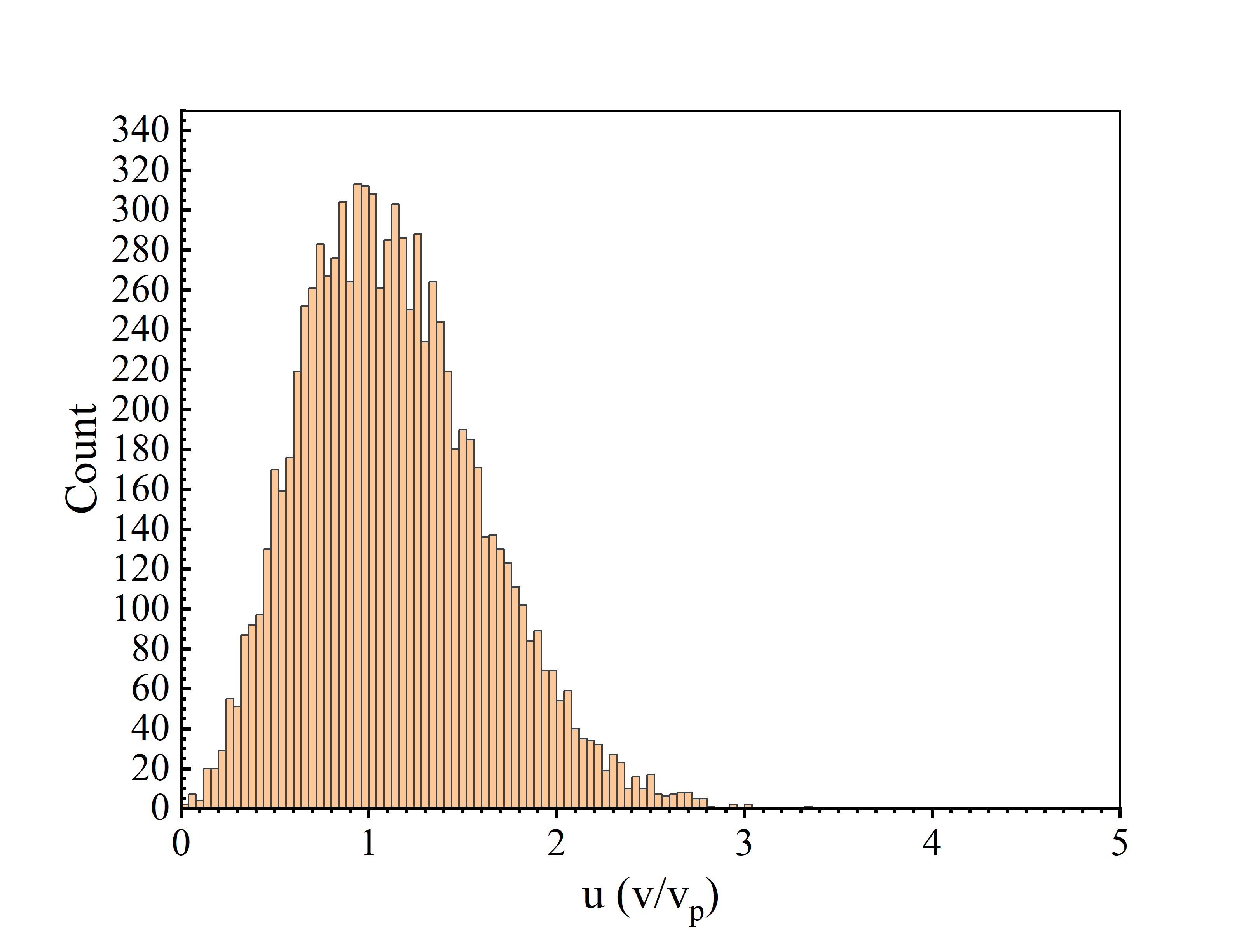
程序整体由三个部分组成,分别是生成单位随机数、Transformation method和Acceptance Rejection method[1]。
生成单位随机数所使用的是Linear congruential generator算法,由于取的modulus比较大,所以能够实现比rand()函数更加精细的生成结果。最初的种子来自系统时间,这就保证了每次生成的结果是不同的。生成的随机数必然是整数,所以要将其单位化,之后还要根据实际需要将其进行平移和伸缩。
Transformation方法的概述如下:设$F(x)$为随机变量$x$的累积分布函数,如果我们取$y=F(x),F(x)\in [0,1]$作为一个新的随机变量,那么$\frac{\text{d}y}{\text{d}x}=F’(x)=f(x)$,所以随机变量$y$所满足的pdf(probability density function)函数为
$$g(y)=f(x)|\frac{\text{d}x}{\text{d}y}|=1$$
也就是$y$实际上服从$[0,1]$上的均匀分布。根据这一点,我们可以反向生成目标分布,因为均匀分布是非常容易实现的。现在我们将$x$视为$y$的函数,那么我们有
$$F(x(y))=\int_{-\infty}^{x(y)}f(t)\text{d}t=y$$
将这个式子积分就得到了$x(y)$和$y$的函数,从中可以(对于比较简单的函数)将$x(y)$反解出来。利用这个关系和已经生成好的$y$,就可以生成服从目标分布的$x$。
Transformation的概念非常清晰,但缺点也是显而易见的:当函数比较复杂的时候反解$x(y)$的工作几乎是不可能的。这时我们可以利用另一种方法——Acceptance Rejection method。
这种方法的步骤如下:(1)生成位于$[x_{min},x_{max}]$的均匀分布的$x$序列;(2)生成位于$[0,f_{max}]$的均匀分布的$u$序列;(3)如果$u<f(x)$,则接受$x$,否则就拒绝$x$。由于在$x$处,$x$被接受的概率正比于$f(x)$,所以得到的分布也是服从$f(x)$的。
然而这种方法也有其缺点:当$f(x)$有尖峰和长尾的时候,效率很低下,往往发生的情况是生成了20个$x$,也不一定有一个能被接受。所以我们可以对这种方法进行进一步的改进:将初始的矩形域修改为小一点的域。也就是首先寻找一个能将$f(x)$包括进去的曲线$g(x)$,然后(1)生成一个服从$\frac{g(x)}{\int g(t)\text{d}t}$的$x$;(2)生成一个服从$[0,g(x)]$均匀分布的$u$;(3)如果$u<f(x)$,则接受$x$,重复以上步骤。但是由于目前缺少关于这种方法的实例,我也没有迫切的改进效率的需求,我暂时没有在程序中包括这种改进后的方法。
以下是程序的源代码:
1 |
|
值此新春佳节,祝福大家新年快乐,新的一年身体健康、万事顺意!